This is the second blog of the Network Indexer blog post series. In this post, we will dive into more details of how Network Indexer works. Find our previous post here: Introduction to Network Indexer.
Earlier this year, Protocol Labs launched the first production Network Indexer to enable searching for content-addressable data available from storage providers, such as those on the Filecoin and IPFS networks. We have now indexed 6B+ content IDs (CIDs), with over 140 Storage Providers publishing their data to Indexer, and 4 production indexer nodes running with our partners. As Indexer nodes process more and more content across Filecoin and IPFS, clients can query the Indexer to learn where to retrieve the content identified by those CIDs.
Overview
Filecoin stores a great deal of data, but without proper indexing, clients can’t perform efficient retrieval. To improve Filecoin content discoverability, Indexer nodes are developed to store mappings of CID multi-hashes to content provider records. A client uses a CID or multihash to lookup a provider record, and then uses that provider record to retrieve data from a storage provider. In short, the indexer works like a specialized key-value store for the following two groups of users:
- Storage providers advertise their available content by storing data in the Indexer. This is handled by the Indexer’s ingest logic.
- Retrieval clients query the Indexer to find which storage providers have the content, and how to retrieve it (i.e. graphsync, bitswap, etc.). This is handled by the Indexer’s find logic.
In the post, we will look into how Indexer components interact with each other, and how indexes are ingested, stored, and shared across network.
Indexer Interactions
So, how do these two user types interact with Indexer?
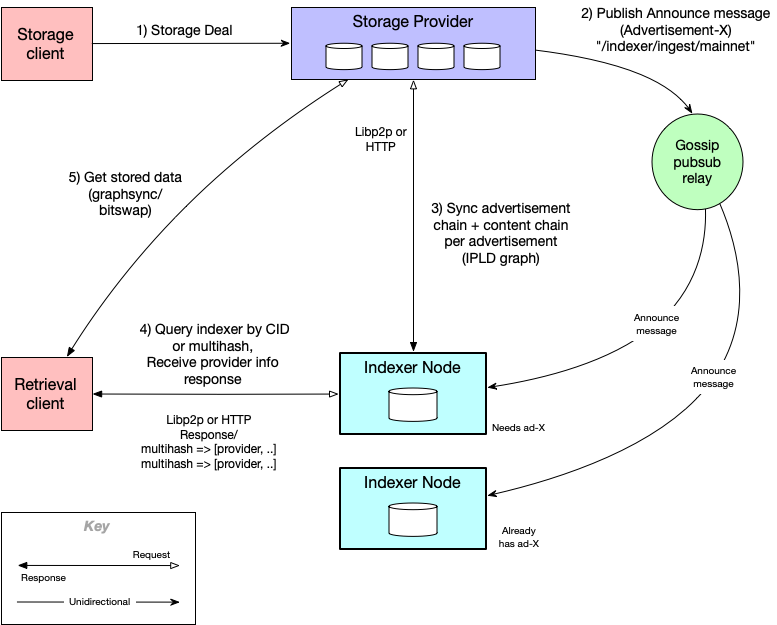
First, a storage deal is made and data is stored by a storage provider. The storage provider will announce that new content is available by publishing the CID of the advertisement record over gossip pubsub, generally relayed by mainnet nodes. Alternatively, it can be sent directly to Indexer via HTTP. Indexer nodes can also relay to each other.
Then, Indexer would sync the new content from storage provider, by getting advertisements in the chain up to last already seen or end of the chain. It would also get contextID, metadata, and content multi-hash chunk chain for each new advertisement.
Once the content is indexed, the retrieval client can find provider data using the CID or multi-hash of the data that they want to retrieve for. Indexer would respond with list of provider records for each CID looked up, along with the latest provider addresses.
Next, the client retrieves the content from storage provider using the protocol indicated in the provider record (e.g. graphsync or bitswap). Client then sends the provider record to the storage provider, who uses contextID and metadata to find the content.
This diagram summarizes the different actors in indexer ecosystem, and how they interact with each other:
Index Ingestion
Index ingestion consists of two parts:
- Publish – Announcing the availability of index advertisements by publishing an announce message to indexer(s).
- Sync – Fetching index data from the publisher of that data. Synchronizes the indexer with the published index data.
Announce Message informs indexers about the availability of an advertisement. It is sent from publisher to indexer, via gossip pubsub (in most cases), or via HTTP. Announcement message contains the CID of the advertisement, and the publisher’s address (where to retrieve the advertisement from). Indexer ignores the announce if it has already indexed the advertisement.
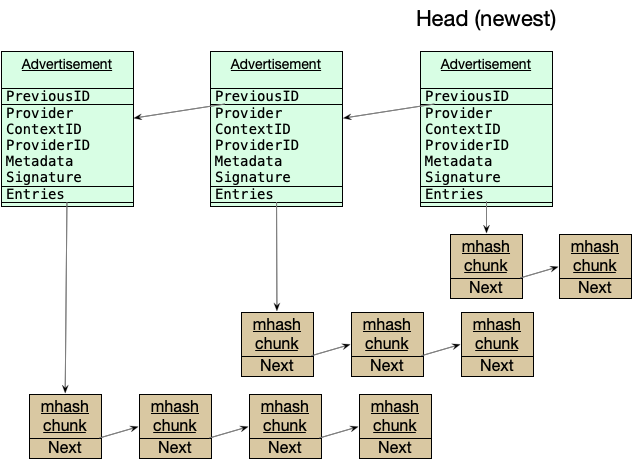
Advertisements are processed in order, and are signed (including links) to create a blockchain-like structure. It must be signed by provider or allowed publisher.
In advertisement, ContextID uniquely identifies a specific metadata for a provider. A ContextID is used to update metadata, add multi-hash mappings to a provider record, or delete a provider record and multi-hash mappings to it. Metadata contains the protocol identifier plus additional data that is forwarded to storage provider when retrieving data. The SP uses the metadata to find the data to retrieve, it may contain a deal ID, internal record keys, etc.
The following diagram illustrates the structure of advertisements and multihash data:
Data Storage
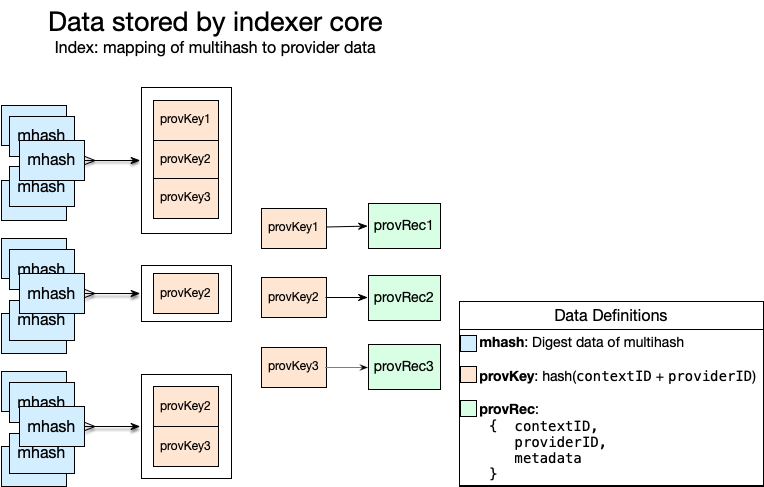
In Indexer data store design, many multihashes map to relatively few provider records. A multihash is used to lookup the provider records describing where the content identified by that multihash is available. A provider ID and context ID are used to lookup a unique provider record.
Provider data can be updated and removed independently from the multihashes that map to it. Provider data is uniquely identified by a provider ID and a context ID. The context ID is given to the indexer core as part of the provider data value. When a provider data object is updated, all subsequent multihash queries will return the new value for that data.
Unique provider records are looked up by a provider key, which is a hash of the provider ID and the record’s context ID. A multihash can map to multiple provider records since the same content may be stored by different provider and be part of separate deals at the same provider. The Indexer core maps each multihash to a list of provider keys, and maps each provider key to a provider record.
This diagram shows the 2-level mapping design of indexer data store:
Data Sharing
Additionally, Indexers can share various types of data with each other when configured to do so.
- Indexers can discover providers and publishers from other indexers.
- Indexers can re-publish HTTP announcements to other indexers.
- Indexers can relay gossip pubsub announcements.
Resources
If you are interested in participating in Indexer network or learning more about Indexers, you may find these resources helpful:
- cid.contact (content routing homepage)
- docs.cid.contact (Indexer gitbook)
- storetheindex (Filecoin slack channel)
- Indexer Implementation
- Valuestore Implementation
- Library for Indexer Synchronization
https://filecoin.io/blog/posts/how-does-the-network-indexer-work/